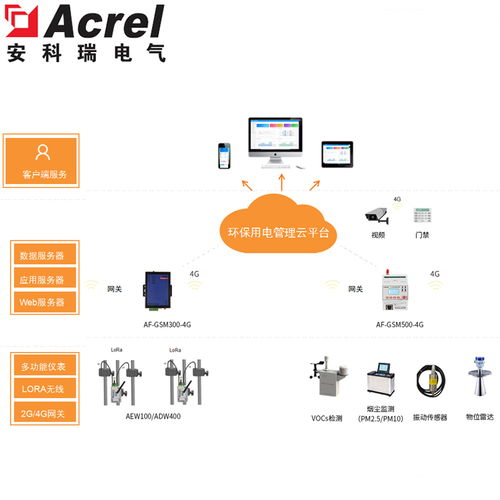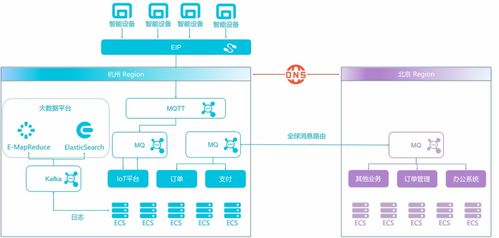
随着企业信息系统规模的不断扩大,运行维护服务面临着数据流复杂、实时性要求高、系统耦合性强等挑战。在此背景下,Kafka消息系统作为一种高吞吐量、可扩展、持久化的分布式消息队列平台,已经成为现代信息系统运行维护服务中不可或缺的核心组件。本章将深入探讨Kafka在信息系统运行维护服务中的应用、优势及最佳实践。
一、Kafka消息系统概述
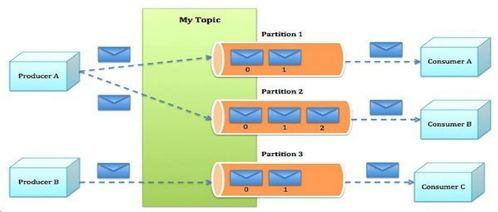
Kafka最初由LinkedIn开发,是一种基于发布/订阅模式的消息系统。其核心设计理念是提供高吞吐量、低延迟的数据处理能力,同时具备强大的容错性和可扩展性。Kafka通过主题(Topic)组织数据流,生产者(Producer)将消息发布到指定主题,而消费者(Consumer)则从主题订阅并处理消息。这种解耦架构使得系统各组件能够独立演进,大幅提升了系统的灵活性和可维护性。
二、Kafka在信息系统运行维护服务中的核心应用场景
- 日志聚合与监控告警:在复杂的分布式系统中,各服务节点会产生海量日志数据。Kafka可以作为统一的日志收集管道,实时聚合来自不同服务器的日志,并转发到监控系统(如ELK Stack)进行分析。运维团队可以通过实时消费这些日志数据,快速定位系统异常,触发告警机制,从而实现主动式运维。
- 数据同步与备份:在多数据中心或混合云架构中,Kafka能够高效同步业务数据、配置变更等信息,确保各环境间的一致性。其持久化存储特性也支持消息重放,为数据恢复和审计提供可靠保障。
- 事件驱动架构支撑:现代微服务架构常采用事件驱动模式,Kafka作为事件总线,能够可靠传递服务间的事件消息,支持服务解耦、异步处理和最终一致性。这在运维自动化场景中尤为重要,如自动扩缩容、故障切换等。
- 实时数据处理管道:运维监控指标(如CPU使用率、请求延迟)可以通过Kafka实时传输到流处理系统(如Apache Flink、Spark Streaming),进行实时分析与可视化,帮助运维人员掌握系统健康状态。
三、Kafka带来的运维服务优势
- 提升系统可靠性:Kafka的分布式设计支持多副本机制,即使部分节点故障,服务仍可正常运行。其持久化存储确保消息不丢失,满足关键业务对数据可靠性的要求。
- 增强扩展能力:运维团队可以按需增加Kafka集群的节点,以线性提升吞吐量,应对业务增长带来的数据压力。消费者组机制也支持水平扩展,提高消息处理能力。
- 降低耦合复杂度:通过引入Kafka,传统紧耦合的系统架构得以解耦,各服务模块独立部署和升级,简化了运维部署流程,降低了变更风险。
- 改善故障排查效率:集中化的消息流为运维提供了完整的数据链路视图,结合监控工具,可以快速追踪问题根源,缩短平均恢复时间(MTTR)。
四、运行维护服务中Kafka的最佳实践
- 集群规划与容量预估:运维团队需根据业务峰值流量规划Kafka集群规模,合理设置分区数、副本因子等参数,并预留一定的性能缓冲空间。
- 监控与告警体系建设:部署针对Kafka的监控方案,跟踪关键指标如吞吐量、延迟、磁盘使用率等,并设置阈值告警,确保集群健康运行。
- 安全与权限管理:在生产环境中启用SASL认证、SSL加密等安全机制,结合ACL(访问控制列表)严格控制主题的读写权限,防止未授权访问。
- 性能调优与故障预案:定期对Kafka集群进行性能调优,如调整JVM参数、优化磁盘I/O。同时制定详细的故障应急预案,包括节点恢复、数据重平衡等操作流程。
- 文档与知识库积累:维护详尽的Kafka运维文档,记录配置变更、故障处理经验,形成知识库,提升团队整体运维能力。
五、未来展望
随着云原生技术的普及,Kafka也在不断演进,如与Kubernetes的深度融合、Serverless模式探索等。运维服务需要持续跟进技术发展,将Kafka与新兴的运维工具链(如可观测性平台、AIOps)结合,构建更智能、高效的信息系统运行维护体系。
Kafka消息系统通过其高可靠、可扩展的特性,为信息系统运行维护服务提供了强大的数据流转支撑。合理引入并有效管理Kafka,不仅能够提升系统的稳定性和性能,还能推动运维模式向自动化、智能化转型,为企业的数字化转型奠定坚实基础。运维团队应深入掌握Kafka的核心原理与实践技能,使其在复杂的系统环境中发挥最大价值。